

python爬虫之爬取掘金网首页存入mysql数据库
博主是个前端小白,最近在学习爬虫,写个实战系列也是想记录自己学习的过程,以便后续回顾
欢迎大家一起交流学习、共同进步
这篇文章达成的效果是爬掘金网的首页的数据存到mysql数据库里
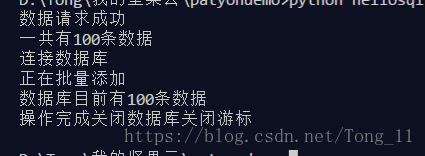
做这个实战你需要具有一点点python的基础知识,当然没有也行可以复制代码先跑一跑感受一下会有动力一点
爬取的网站:https://juejin.im/timeline
系统:win10
python版本:3.7
MYSQL安装包下载:https://dev.mysql.com/downloads/windows/installer/

mysql-installer-web-community 15.9M那个是在线安装
mysql-installer-community 推荐下载第二个离线安装
现在这个安装包好像不分32位还是64位,我是64位的安装成功,MSI安装版安装挺简单的我就不赘述了(其实我安装蛮久了没记录下来)
安装完成可以通过·mysql -u root -p查看
mysql安装成功后你还需要一个python操作mysql的库,cmd执行使用pip安装pymysql:
pip install pymysql
环境准备好后就开始愉快的学习吧
网站分析
我们进入网站https://juejin.im/,然后打开f12(博主用的是chrome浏览器,在前端眼里chrome是最好浏览器没有之一)
掘金网是个动态网站,即客户端(浏览器)根据服务端(服务器)返回的数据动态渲染网页
那么数据从哪儿来,服务端会根据客户端不同的请求或者请求参数的差异来返回数据
这里我们需要登陆下,我们登陆成功即通过服务端验证后服务器会签发一个 Token发送给客户端,你可以理解为一个验证身份的令牌,客户端收到 Token 以后把它存储起来,每次向服务端请求资源的时候都需要带着这个token,服务端收到请求,去验证客户端请求里面带着的 Token,如果验证成功,就向客户端返回请求的数据
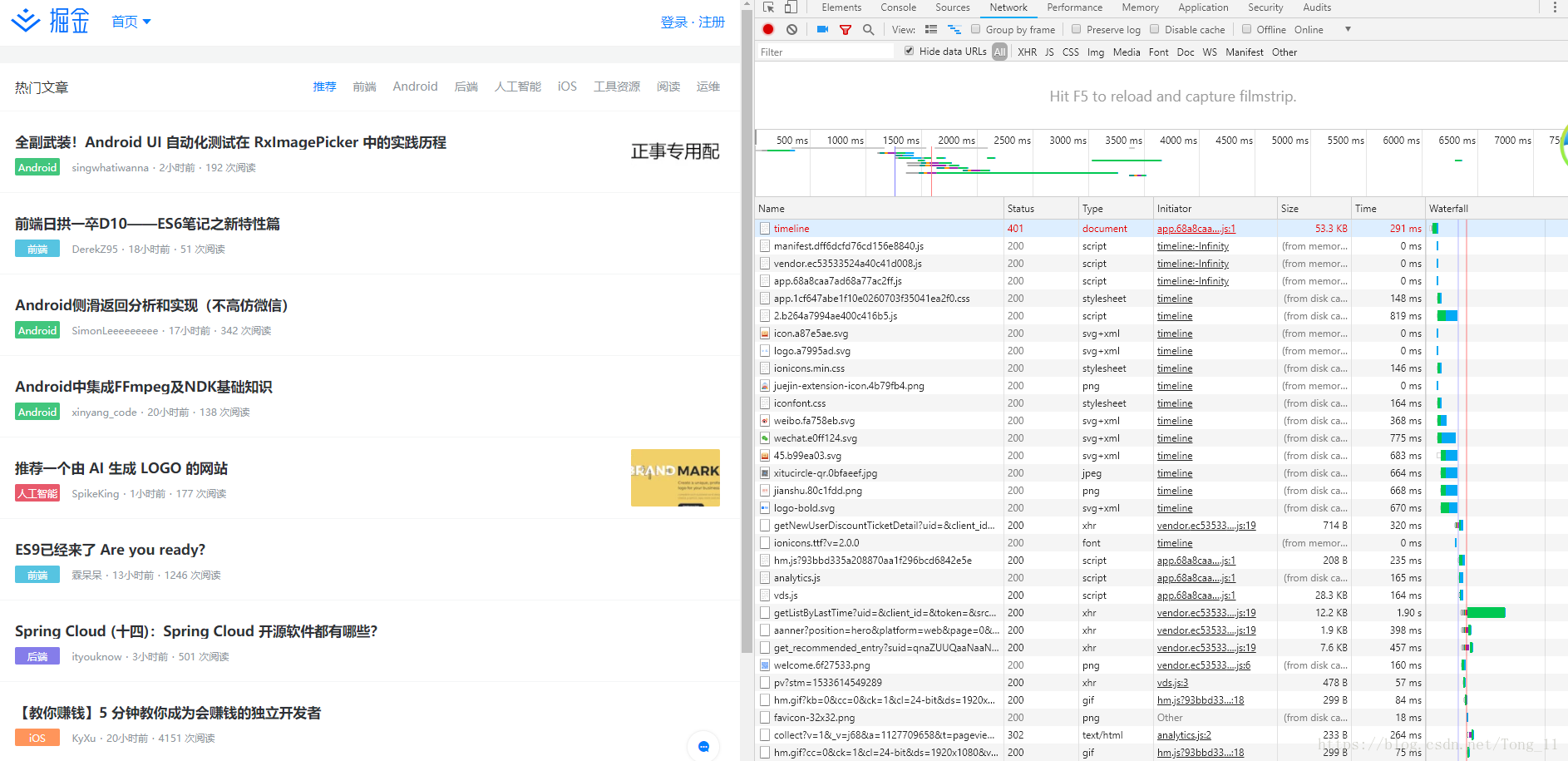
我们可以看到有很多请求,什么图片、脚本资源、svg很多
点击XHR按钮过滤请求只显示XMLHttpRequest方法发送的请求

过滤之后现在挨着查看,找到返回文章数据的那条请求
大部分数据都是页面或者服务器做判断用的,我们提取这些参数就好
[‘category’][‘name’] 文章分类
[‘title’] 文章标题
[‘content’] 文章概要
[‘originalUrl’] 文章链接
[’tags’] 文章标签
[‘user’][‘username’] 文章作者
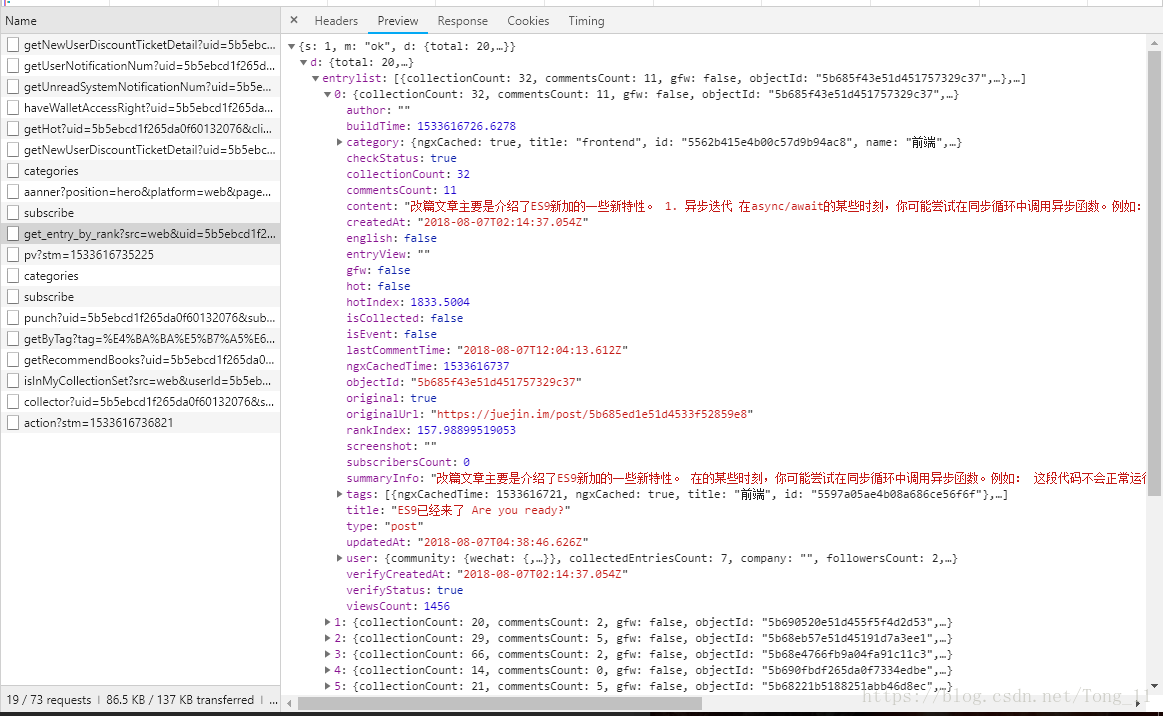
然后我们查看他的Headers,滑到底部可以看到uery string params是由客户端发给服务器时请求携带的参数

这些参数里面有个limit是请求的条数,就是你请求多少条就会返回多少条数据
现在上代码
需要3个库,除了第一个pymsql以为都是python自带的
1 | import pymysql # 操作mysql的库 |
我们先发送请求获取数据
1 | def juejin_req(data_num): # data_num是请求的条数 |
打开workbench,这是自带的一款可视化的sql操作工具
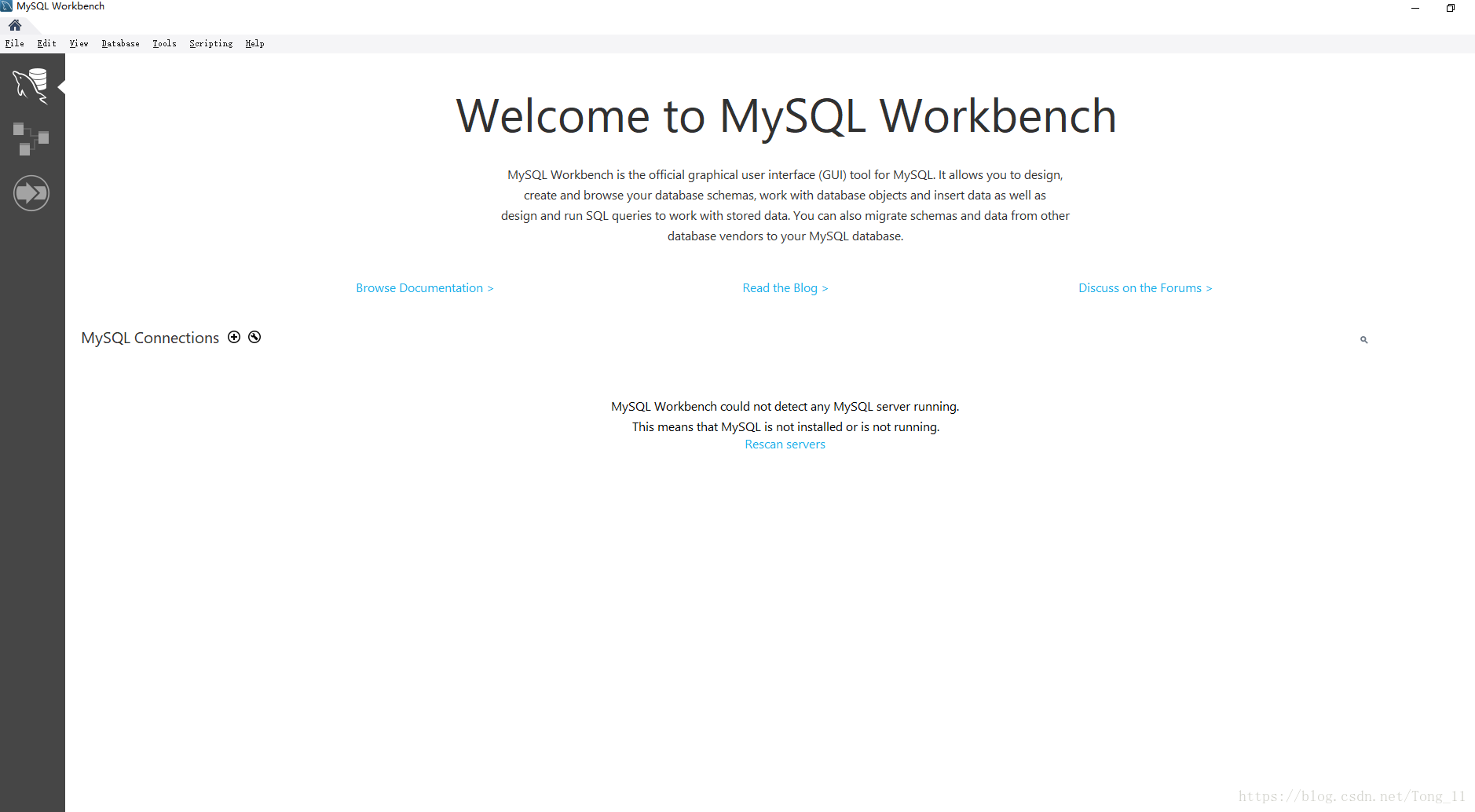
首先我们先新建一个连接
点击新建一个连接—–填上连接名字hellosql—–点击ok—–在弹出的弹框中输入你的密码–点击ok
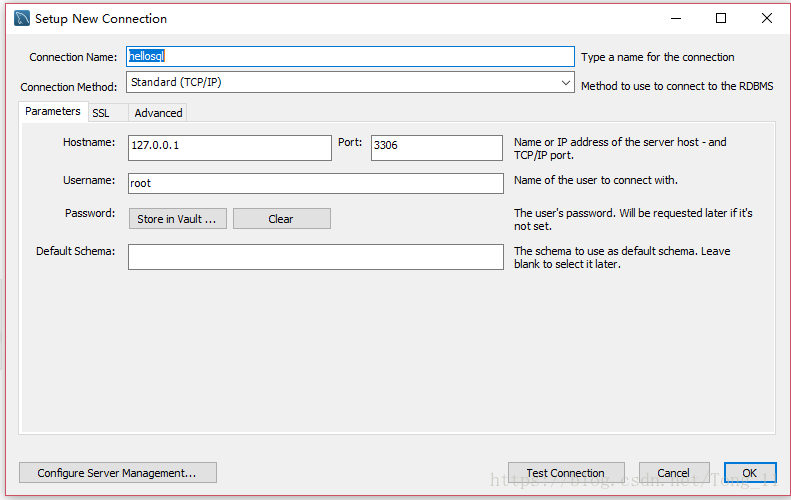
连接建立后我们新建一个数据库,在左侧红圈空白地方右键—create scheme(新建一个数据库),这地方我已经建了
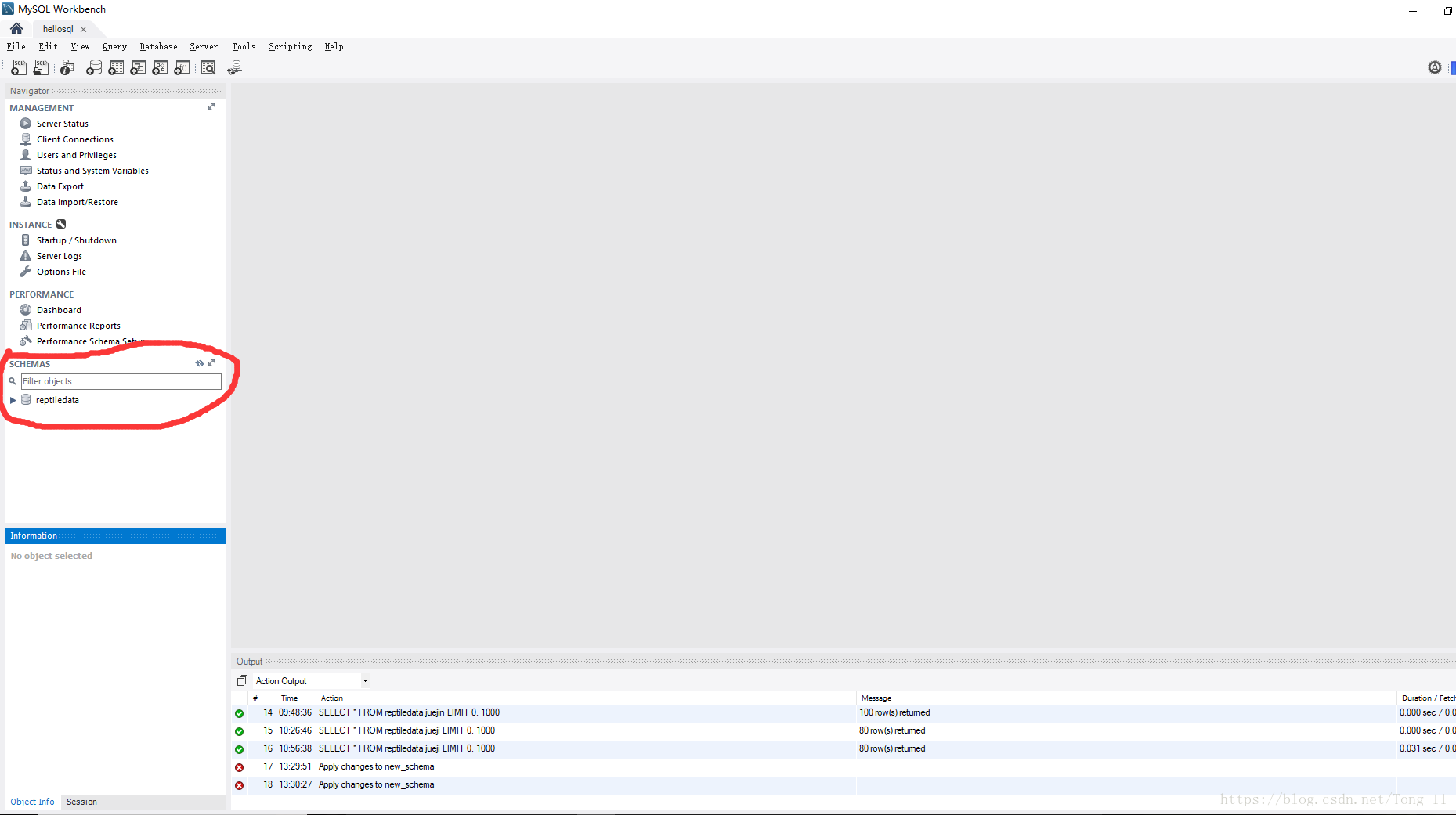
输入数据库名字reptiledata—点击apply—出现一个弹框继续点击apply,这样我们就新建了一个数据库
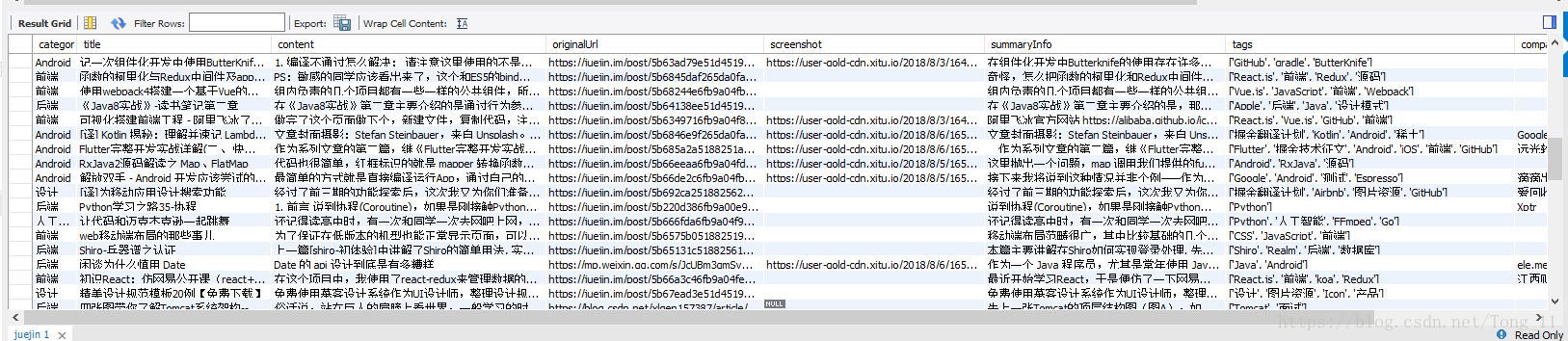
这是操作数据库的代码,获取到请求的数据后将数据return处理在传给juejin_sql函数,所以把这段代码放在上面那段代码后面
1 | def juejin_sql(sql_data): |
欢迎留言交流 (´▽`ʃ♡ƪ)