

python爬虫之selenium自动化测试让你爬虫更像用户
全程序自动化操作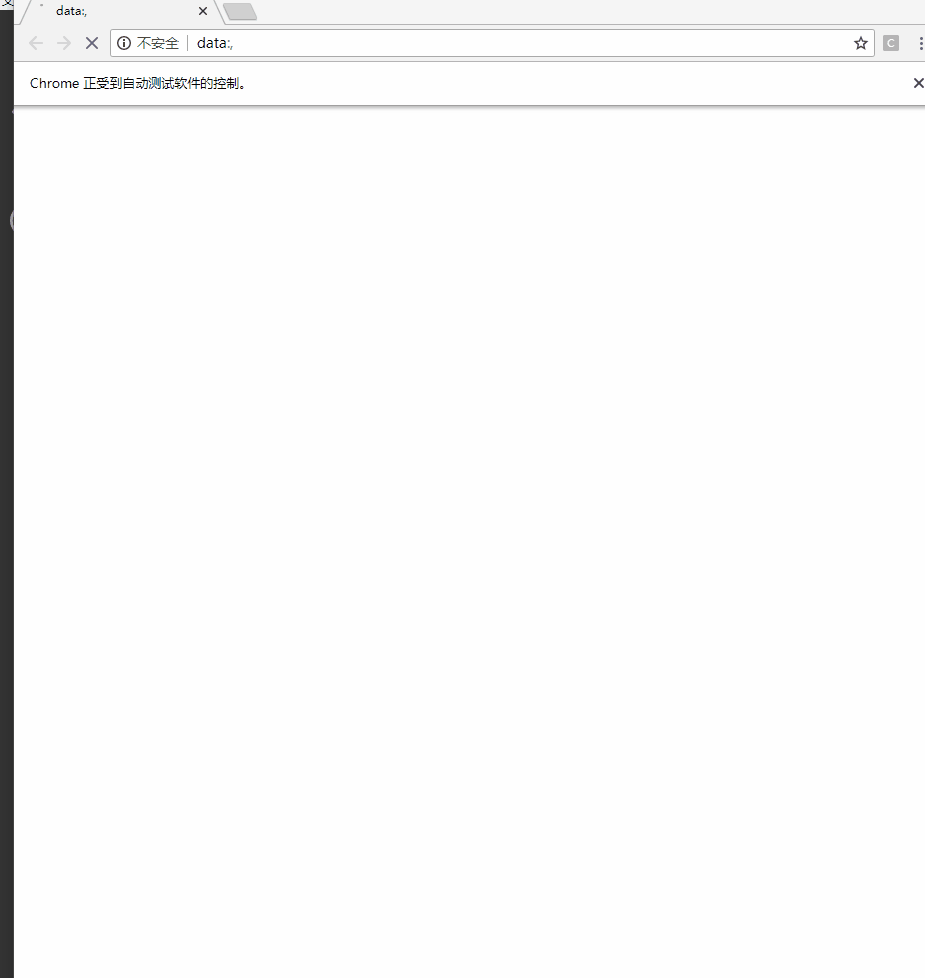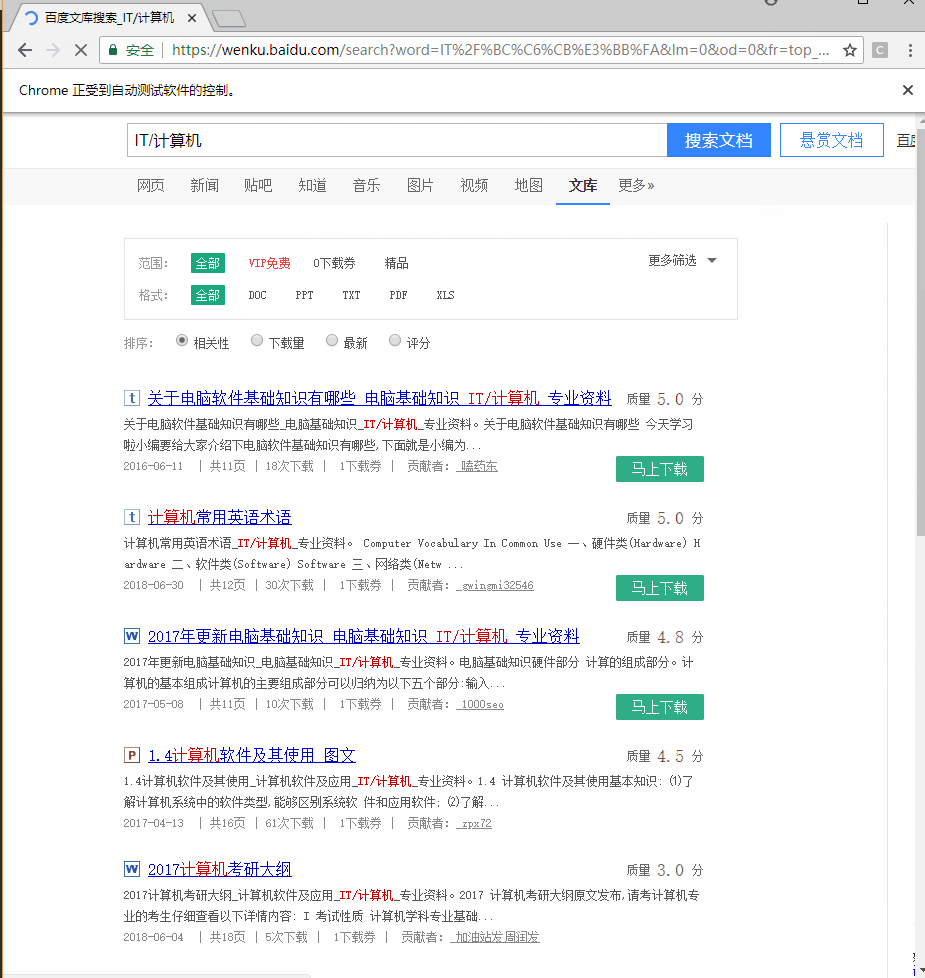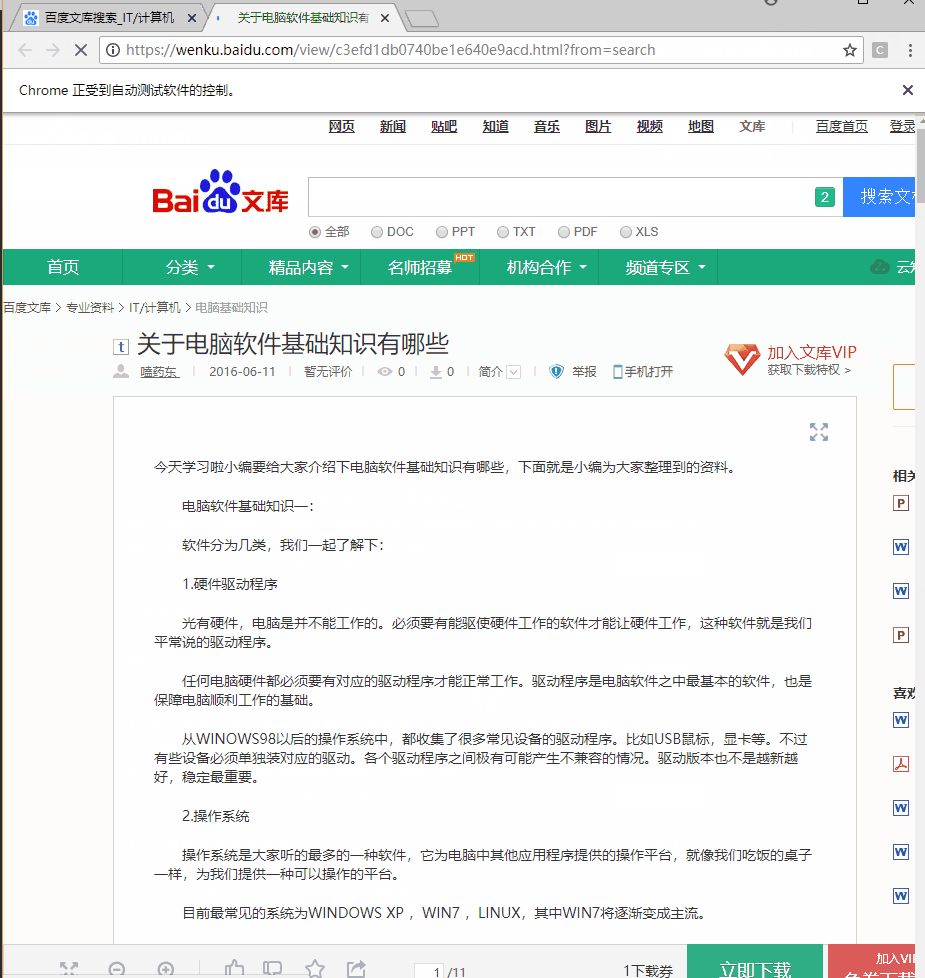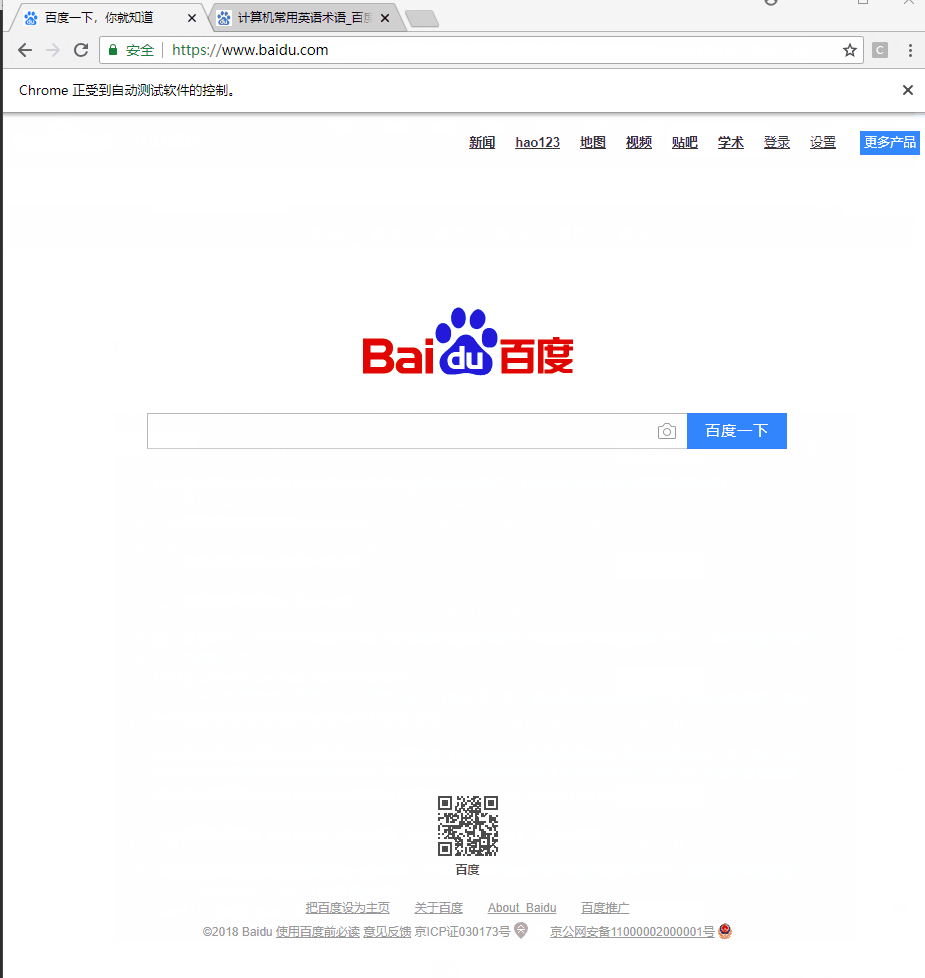
先科普一下selenium,这是一个用于Web应用程序测试的工具,支持多种浏览器多种语言
框架底层使用JavaScript模拟真实用户对浏览器进行操作,Selenium测试直接运行在浏览器中,代码执行时,可以自动打开浏览器/表单输入/按钮点击,就像真实用户在操作的一样
真真是反爬虫的一大神器啊
关于安装
1 | cmd命令:pip3 install selenium |
下载谷歌驱动安装:https://sites.google.com/a/chromium.org/chromedriver/downloads
放在谷歌文件夹C:\Program Files (x86)\Google\Chrome\Application下再把这路径加入环境变量
基础知识
Xpath是非常强大的元素查找方式,它可以定位到页面上的任意元素
我这里只介绍了一些今天这个实例会用到的
首先先了解一下它的一些语法
// : 相对路径,以这个开头表示从寻找文档的根节点开始查找元素,若出现在xpath路径中则表示寻找父节点下任意符合条件的子节点,不管嵌套了多少层级
/:绝对路径,表示寻找父节点下的第一层子元素也就是直接子元素
“//标签名[@属性名=’属性值’]”:表示从根目录查找和标签名、属性值相匹配的元素
几乎所有的Xpath路径都是以上面3种方法来组合的
精准定位
以下面这个百度文库这段html举例

要获取输入框怎么写,写法不只一种哈,这地方你也可以直接使用input的id获取元素(一个页面正常来讲不会有相同的id)
input = browser.find_element(By.XPATH, “//form[@name=’ftop’]//input[@id=’kw’]”)
上面这行是用的是find_element是查找单个元素,api在下面可以先看下
表示从根目录查找第一个匹配路径 name为flop的form标签 ,找到这个元素之后再去他所有子元素里面查找id为kw的input框
假设这个页面有两个name为ftop的form标签(name一样的form标签讲道理一个页面是不会有两个现在只是假设,有可能你会遇到class名一样的div标签)
那么获取第二个form标签:”//form[@name=’ftop’][2]//input[@id=’kw’]”, 就在大括号后面加上他的索引,索引是从1开始的
模糊定位
contains关键字:input = browser.find_element(By.XPATH, “//input[contains(@id, ‘kw’)]”)
表示寻找页面中id属性值包含kw所有input元素
text关键字:input = browser.find_element(By.XPATH, “//button[contains(text(), ‘搜索’)]”)
表示寻找页面中文字中包含有搜索的所有button元素
starts-with关键字:input = browser.find_element(By.XPATH, “//a[starts-with(@href,’http://‘)]”)
表示寻找页面中href属性以http://开头的a标签
ends-with关键字:input = browser.find_element(By.XPATH, “//a[ends-with(@href,’com’)]”)
表示寻找页面中href属性以’com’结尾的a标签
关于ends-widh我在使用的时候会报错提示语法不正确而且网上关于ends-with介绍也很少所以我没有找到原因如果大家知道欢迎留言告诉我不胜感激 (´▽`ʃ♡ƪ)
这是一个简单的关于用selenium和xpath来做模糊查询的小实例
1 | chrome_options = Options() |
selenium的一些常用api
find_element和find_elements的使用
browser.find_element(By.XPATH, ‘//button[text()=”Some text”]’) //单个元素获取
browser.find_elements(By.XPATH, ‘//button’) //多个元素获取
ID = “id”
XPATH = “xpath”
LINK_TEXT = “link text”
PARTIAL_LINK_TEXT = “partial link text”
NAME = “name”
TAG_NAME = “tag name”
CLASS_NAME = “class name”
CSS_SELECTOR = “css selector”
单个元素选取(多个元素选取:就是在element后面加一个s,比如find_elements_by_id):
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
获取到标签之后的界面交互:
input.send_keys(“输入中”)
input.clear() 清空输入框
button.click() 按钮点击
常用的控制浏览器的api:
browser.back() 浏览器后退
browser.forward() 浏览器前进
browser.get(“https://www.zhihu.com/explore") 打开页面
browser.execute_script(“alert(‘To Button’)”) 执行js代码
print(browser.window_handles) 所有的标签
browser.switch_to_window(browser.window_handles[1]) 切换到指定标签页
browser.close() 关闭当前标签页
代码实例
关于页面模块引入
1 | # 引入浏览器驱动 |
功能代码
1 | chrome_options = Options() |
开启无头模式
只需要修改一行代码
1 | browser = webdriver.Chrome(chrome_options=chrome_options) |
欢迎留言交流 (´▽`ʃ♡ƪ)