

(译)可视化 JavaScript 引擎
可视化 JavaScript 引擎
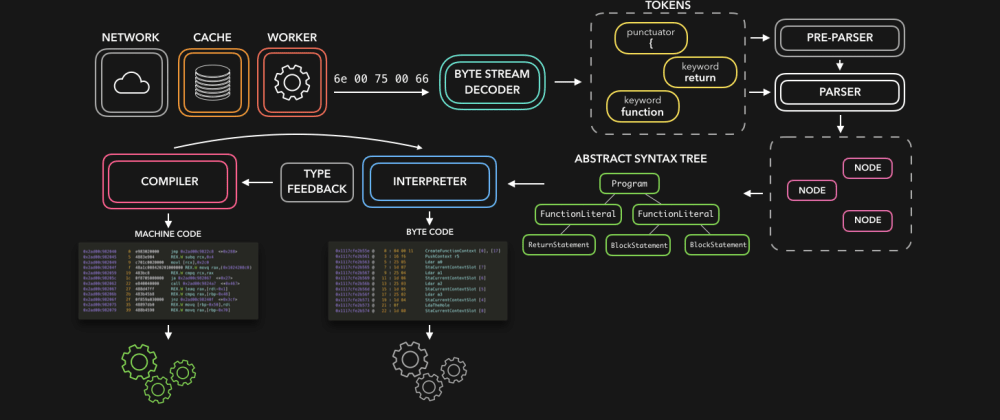
作为 JavaScript 开发人员,我们通常不需要亲自与编译器打交道。但知晓 JavaScript 引擎的基础知识,以及了解它是如何处理我们各自不同的 JS 代码并将其转化为机器能理解的东西,也是很好的!🥳
注意: 这篇文章主要基于 Node.js 和以 Chromium 为基础的浏览器使用的 V8 引擎。
HTML 解析器在你的代码中寻找 script 标签以及其对应的来源,并从其来源加载程序或代码。它可能来自 网络,临时存储,或者其它service worker。然后以字节流的格式响应,稍后该字节流将被字节流解码器接管!主要是字节流解码器会解码到来的流数据。
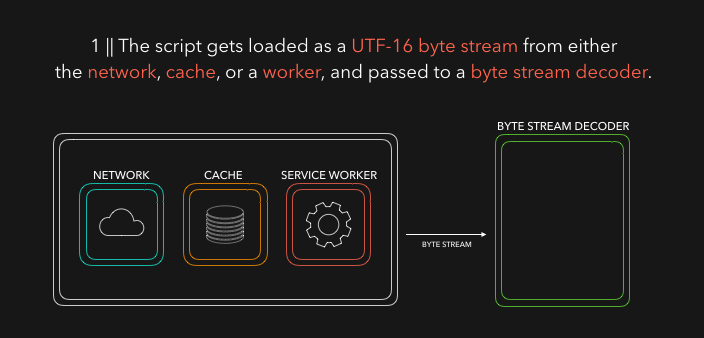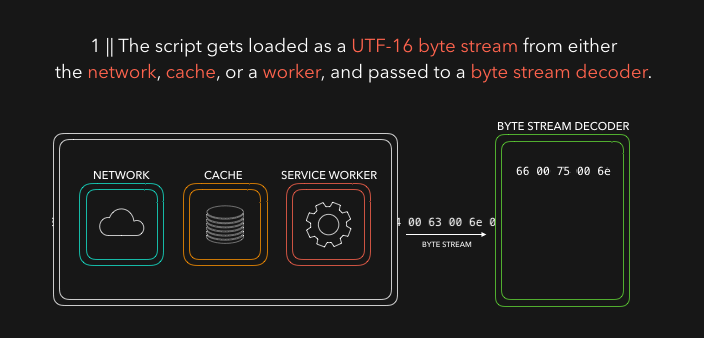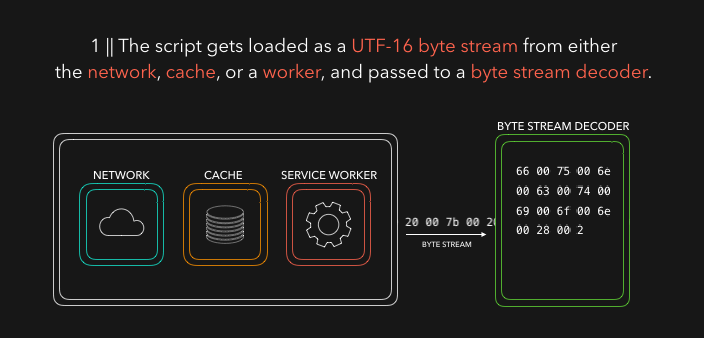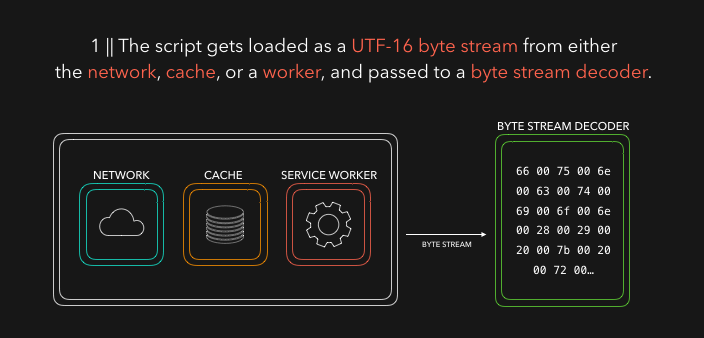
字节流解码器根据已解码的的字节流创建 token。比如,0066 解码为 f,0075 变 u,006e 变 n,0063 变 c,0074 变 t,0069 变 i,006f 变 o,006e变为n` 和一个空格。看上去好像是你写了 function!这在 JavaScript 中是一个保留关键字,一个 token 被创建并发送给解析器(以及预解析器,这并没有涵盖在动图里但稍后会解释)。其余字节流的处理也一样。

引擎使用两个解析器:预解析器(pre-parser)和解析器(parser)。为了减少网站加载花费的时间,引擎会尽量避免去解析不会被立即使用的代码。预解析器处理可能稍后会用到的代码,而解析器处理马上需要使用的代码。如果一个函数只会在用户点击按钮后被调用,那么没有必要一定要在网站加载时编译它。如果最终用户点击了按钮且需要这段代码,那么它会被发送给解析器。
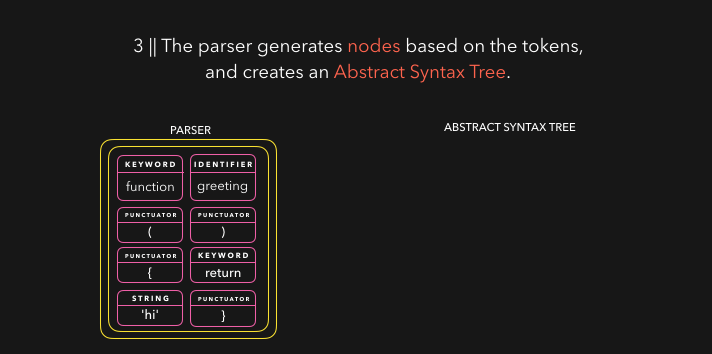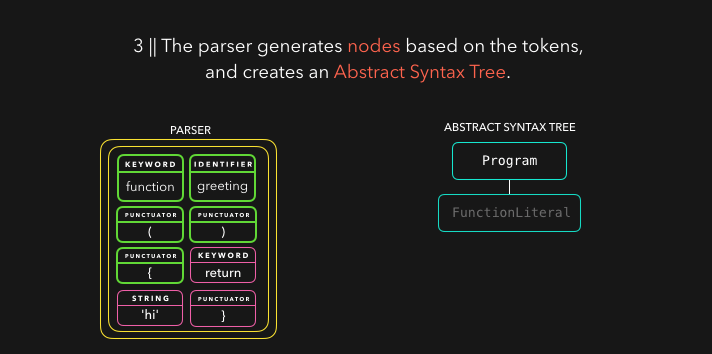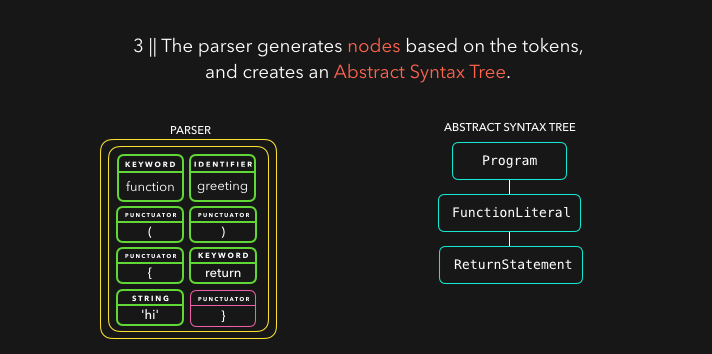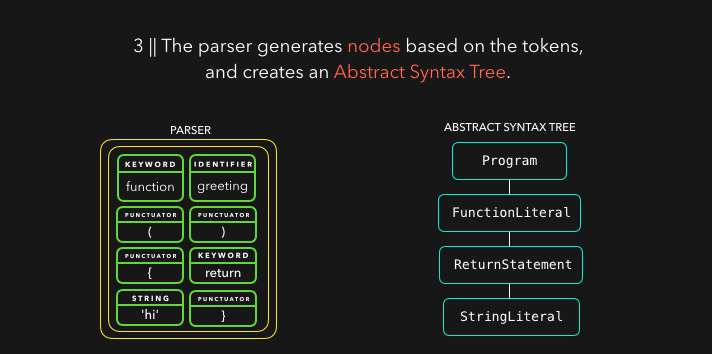
解析器根据从字节流解码器处接收的 token 来创建节点,并用这些节点来创建一个抽象语法树(AST)。🌳
下一步,解释器出场!解释器遍历 AST 并根据 AST 所包含的信息来生成字节码。一旦字节码生成完毕,AST 就会被删除从而清空内存空间。最后,我们就拥有了机器可以使用的东西。🎉

尽管字节码很快,但它还可以更快。字节码运行时会生成一些信息。它可以检测到某些行为是否经常发生以及被使用的数据类型。可能某个函数你调用了几十次,那么是时候做优化了,使其运行速度更快。🏃🏽♀️
字节码以及产生的类型反馈会一起发送给优化编译器。优化编译器接收字节码和类型反馈,并从中生成高度优化后的机器码。🚀

JavaScript 是动态类型的语言,这代表数据类型可以不断改变。如果 JavaScript 引擎每次都需要检查某个值的数据类型,这会导致其运行速度非常缓慢。
为了减少代码解释的时间,优化后的机器码只处理引擎在运行字节码时之前见过的情况。如果我们重复使用某段代码,该代码一遍又一遍的返回相同的数据类型,那么为了加快运行速度,就可以简单的再次使用优化后的机器码。然而,JavaScript 是动态类型,相同的代码可能会突然返回一个不同的数据类型。如果发生了这种情况,机器码性能会退化,引擎会退回到解释已产生的字节码的步骤。
如果某块代码被调用 100 次,而且到目前为止返回相同的值。那么引擎会假设,当你第 101 次调用的时候依然返回该值。
比如说我们有一个如下所示的求和函数,目前为止该函数每一次调用都会带有数字类型的参数。

该函数会返回数字 3!当我们再次调用时,引擎会假定我们依然携带两个数字类型的参数。
如果这是真的,那么就不需要动态检查,引擎可以再次使用优化后的机器码。反之,如果该假设不正确,那么引擎会退回到使用原来的字节码而不是优化的机器码。
比如下一次调用它时我们传递的是字符串而不是数字。因为 JavaScript 是动态类型语言,我们可以这样做而且不会引发报错。

这意味着数字 2 将会强制转为字符串,而该函数将会返回字符串 "12"。引擎将回退去解释字节码以及更新类型反馈。
我希望这篇文章对你有帮助!😊 当然,还有很多有关引擎的知识点在这篇文章内我没有介绍(JS 堆,调用栈等等),这些我可能稍后会涵盖。如果你对 Javascript 内部运作感兴趣,我非常鼓励开始自己做一些研究,V8 是开源的,而且有一些很棒的文档是关于它如何在后台工作的。🤖
感谢阅读,祝你有美好的一天!❤
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。